Split Cost Allocation Data
通过 Split Cost Allocation Data for Amazon EKS,可以根据 Kubernetes 应用程序消耗共享 EC2 CPU 和内存资源的方式,将应用程序成本分配给各个业务部门和团队。
监控和分配容器成本的挑战
获取 Kubernetes 成本的精细可见性并不容易,这是因为传统的 FinOps 成本分配(例如将资源成本映射回团队或项目)不起作用。我们不能简单地将资源(如 EC2 实例)的成本分配给标签或标记,因为 EC2 实例可能运行多个容器,每个容器支持不同的应用程序,这些资源也可能附属于组织内的不同成本中心。对共享 AWS 资源(如 Amazon EC2 实例)的 Amazon EKS 上运行的应用程序进行更精细的成本分配可见性,是一个常见的需求。
虽然AWS用户可以使用 CUR 跟踪其 Kubernetes 控制平面和 EC2 成本,但他们需要更深入的洞察,以准确跟踪按命名空间、集群、Pod 或组织实体(如按团队或应用程序)的 Kubernetes 资源级别成本。
通过 Split Cost Allocation Data 获取 EKS 的精细成本可见性
使用 Split Cost Allocation Data,可以根据 Kubernetes Pod 实际消耗的 CPU 和内存,轻松地在 Kubernetes Pod 级别分配 Amazon EC2 实例成本。容器级别的精细成本信息使我们能够分析容器化应用程序的成本效率,
启用 Split Cost Allocation Data 后,它将扫描我们账单中所有 EKS 集群中的所有 Kubernetes Pod,并摄取 Kubernetes 属性,如命名空间、节点、集群以及 Pod 的 CPU 和内存请求。
Split Cost Allocation Data 还将读取我们的 Amazon Managed Service for Prometheus 工作空间,以引入 Kubernetes CPU 和内存利用率指标。然后,它会计算 Kubernetes Pod 级别的成本指标,例如,分割成本、未使用成本、实际使用情况和预留使用情况(即资源请求),包括折扣后的净成本指标,并在我们的 AWS 成本和使用报告中提供这些信息。
Split Cost Allocation Data 将为一些 Kubernetes 属性创建新的成本分配标签。这些标签包括 aws:eks:cluster-name、aws:eks:namespace、aws:eks:node、aws:eks:workload-type、aws:eks:workload-name 和 aws:eks:deployment。
开始使用 Split Cost Allocation Data
要启用"Split Cost Allocation Data”,我们需要完成一个简单的两步。
步骤 1:首先,在payer帐号,我们需要从 Billing and Cost Management -> AWS Cost Management Preference页面选择"Split Cost Allocation Data”。
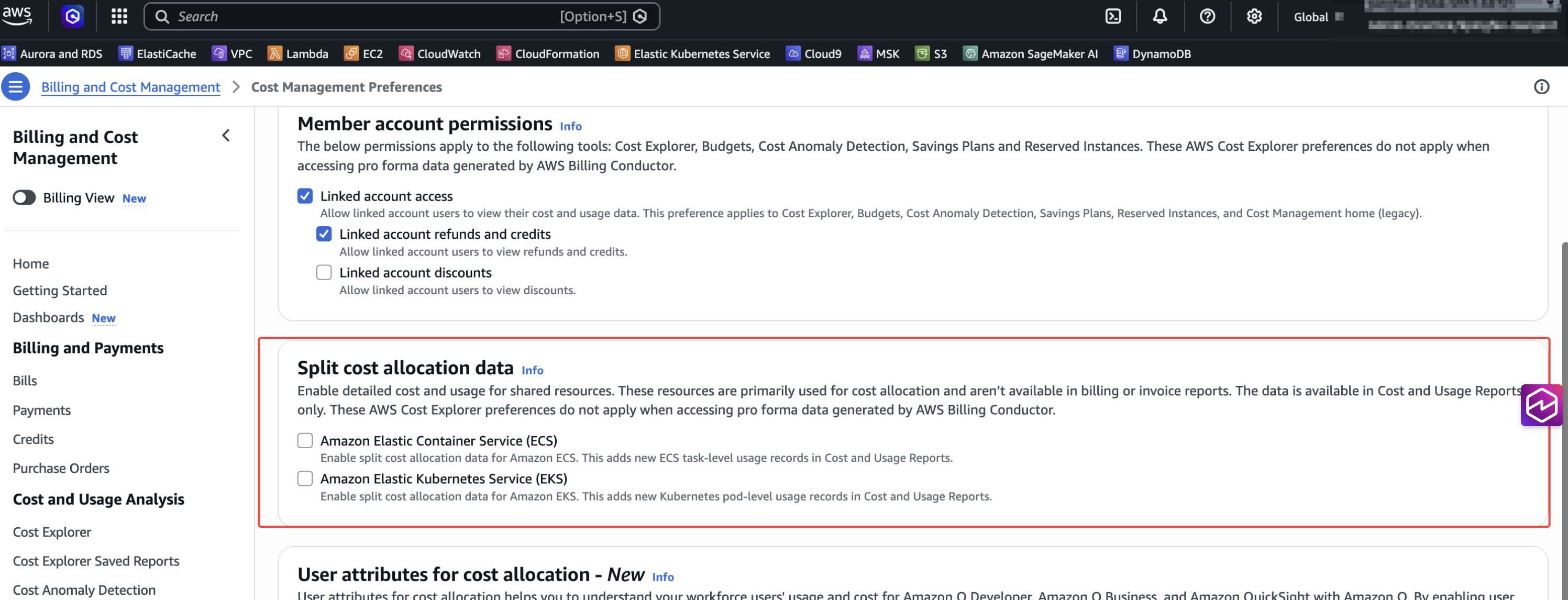
在这里,我们选择 Amazon Elastic Kubernetes Service, 有三个额外选项。
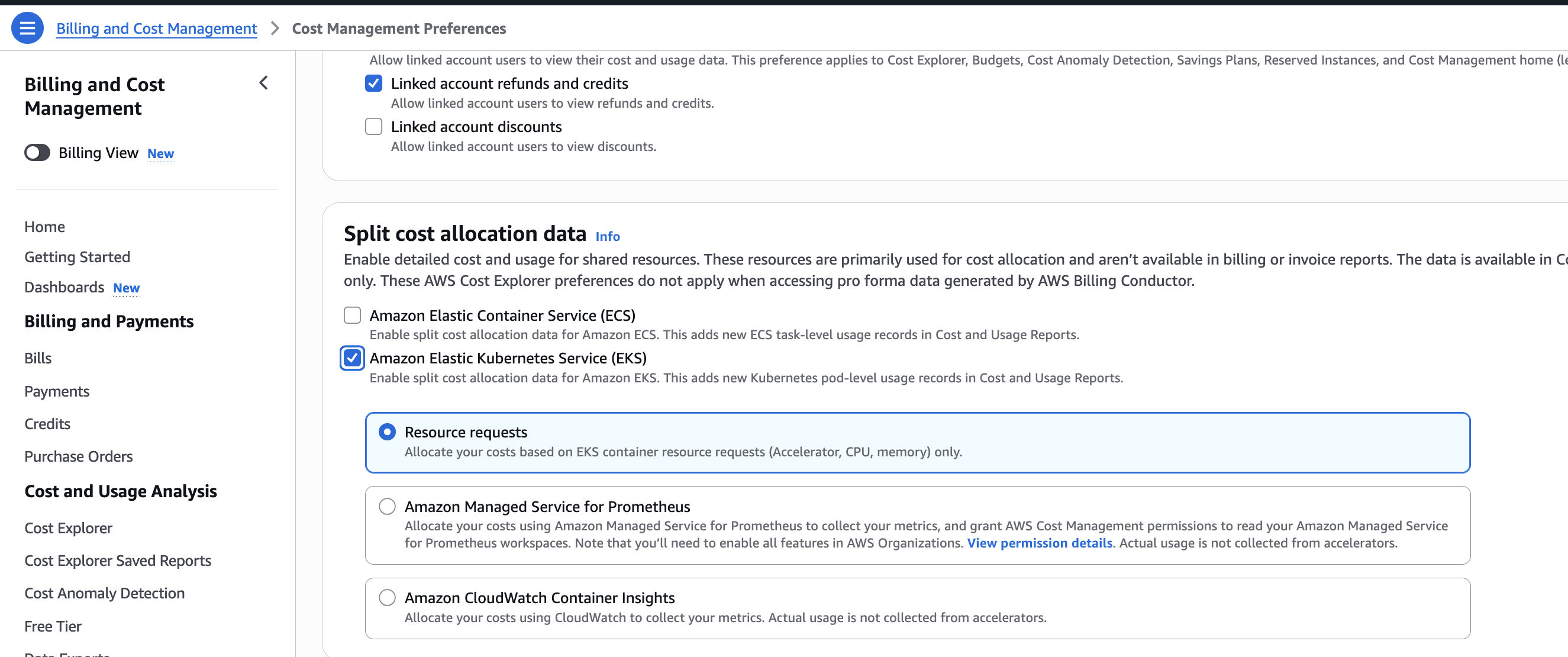
- Resource requests:支持仅按 Kubernetes Pod CPU 和内存资源请求分配 EC2 成本。按资源请求分配成本鼓励应用程序团队只配置他们需要的资源。
- Amazon Managed Service for Prometheus / Container Insights:支持按 Kubernetes Pod CPU 和内存资源请求与实际利用率的较高值分配 EC2 成本。这确保每个应用程序团队为他们使用的资源付费。
步骤 2: 在 AWS Billing and Cost Management 控制台的Data Exports页面为新的或现有的 CUR 2.0 报告启用"Split Cost Allocation Data”。
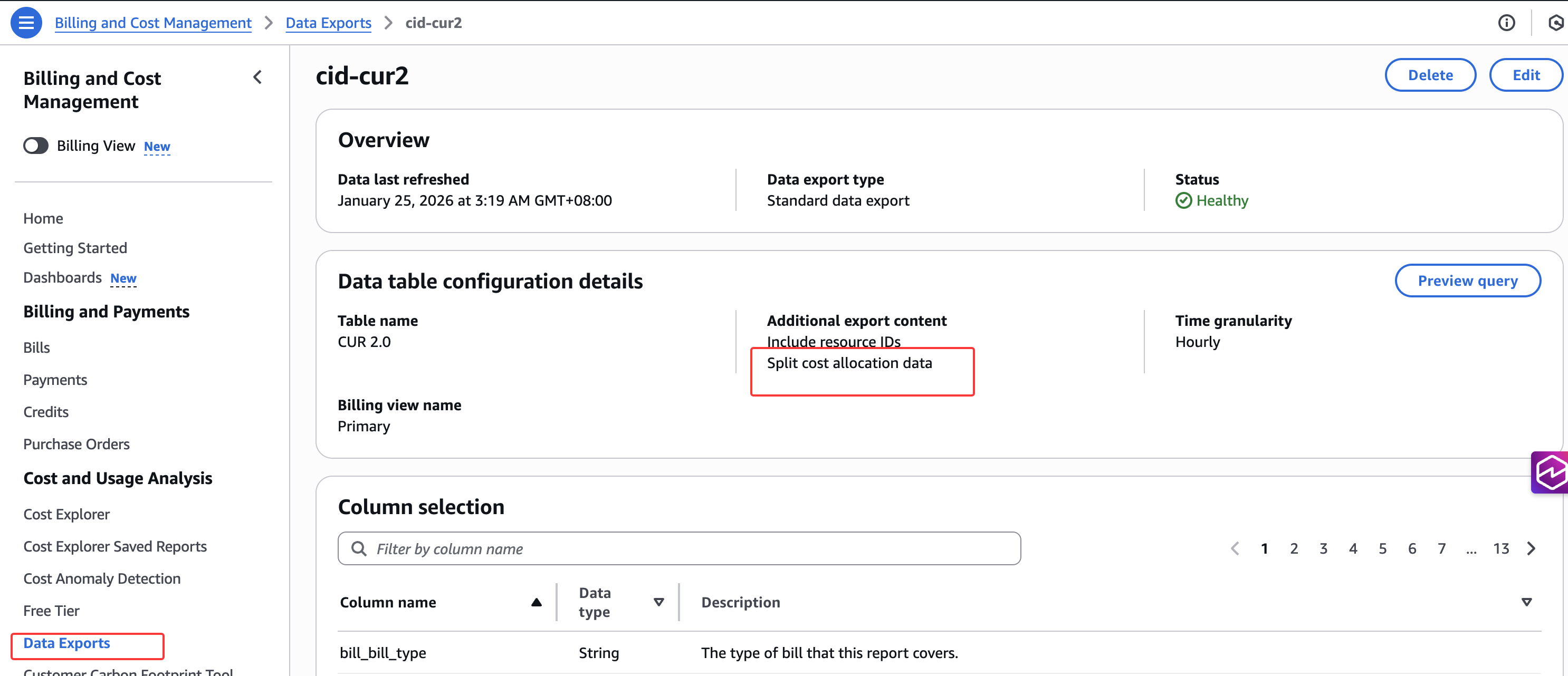
启用后,在 24 小时内,我们的 CUR 报告将准备好,其中包含新的 EKS 成本和使用指标。
工作原理
EKS 的 Split Cost Allocation Data 收集与 EKS 集群关联的每个 EC2 实例的计算和内存资源的请求和实际使用数据。只有当我们选择了 Amazon Managed Service for Prometheus 时,才会收集实际使用数据。
如果我们选择了Resource requests求选项,则实际使用被视为 0。然后,它根据请求量和使用量之间的较大值计算每个 Kubernetes Pod 的分配 CPU 和内存数据。
由于多个 Kubernetes Pod 可以在单个 EC2 实例上运行,EKS 的 Split Cost Allocation Data 计算实例上所有 Pod 的分配 CPU 和内存。然后,它计算一个分割使用比率(split-usage-ratio),即分配给每个 Kubernetes Pod 的 CPU 或内存与 EC2 实例上可用的总 CPU 或内存的百分比。它还识别实例上剩余的未使用容量。
在所有 Kubernetes Pod 之间共享 EC2 实例的成本时,Split Cost Allocation Data 总计分割成本,然后根据 Pod 的实例利用率按比例重新分配未使用的成本。
让我们举个例子
示例:多个 Kubernetes Pod 之间的 EC2 成本分配
下面我们可以看到一个 EKS 集群在一个 m7g.2xlarge EC2 实例节点上运行,该实例有 8 个 vCPU 和 32GB RAM。该集群在单个 Amazon EKS 集群内的 2 个命名空间中运行 4 个 Kubernetes Pod。我们将使用 m7g.2xlarge 的按需定价进行演示,但请注意,Split Cost Allocation Data 将使用 EC2 实例的摊销成本(如果 EC2 实例上有 Savings Plan 或预留实例,则包括预付和部分预付费用)。Split Cost Allocation Data 使用基于 9:1 比率的 CPU 和内存的相对单位权重。这是基于 AWS Fargate 定价 的 vCPU 与内存的平均相对价格得出的。使用这些权重,它计算每 vCPU 小时的成本和每 GB 小时的成本分别为 $0.029 和 $0.003。

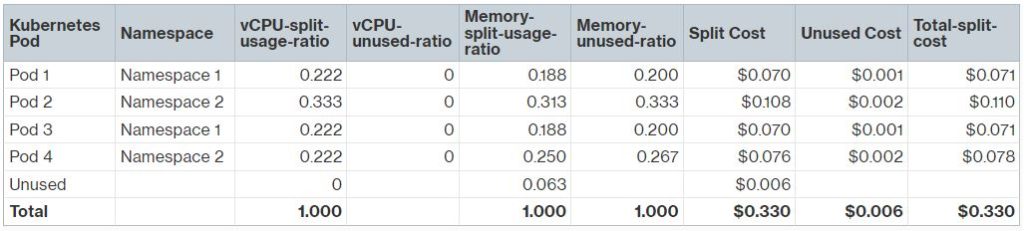
下表列出了 4 个 Kubernetes Pod 的 vCPU 和内存请求以及实际使用情况。Pod 2 使用的 CPU 和内存比请求的多,因为它没有配置limit。如前所述,Split Cost Allocation Data 根据请求和实际使用情况之间的较大值计算分配的 vCPU 和内存。在这个例子中,我们没有未使用的 vCPU,但有 2GB 的未分配内存。
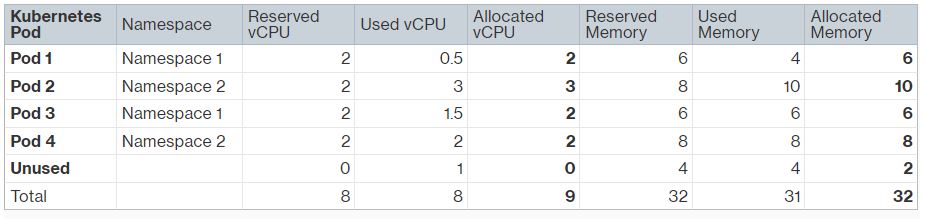
Split Cost Allocation Data 计算分割使用比率,即 Kubernetes Pod 分配的 CPU 或内存与 EC2 实例上可用的总 CPU 或内存的百分比。它还计算未使用比率,即 Kubernetes Pod 分配的 CPU 或内存与 EC2 实例上分配的总 CPU 或内存的百分比(即,不考虑实例上未分配的 CPU 或内存)。例如,实例上有 2GB 的未分配内存,这是总实例内存的 2/32 = 0.063。Pod1 分配了 6GB,这是总实例内存的 6/32 = 0.188。因此,Pod 1 的总未使用内存比率为 0.188 / (1-0.063) = 0.200。
Pod 级别的分割成本是根据分割使用比率乘以每 vCPU 小时的成本和每 GB 小时的成本计算的。如果有未使用的资源,在这种情况下,未使用的内存容量为 2GB,未使用的实例成本($0.006)将根据为每个 Pod 计算的未使用比率按比例分配给每个 Pod。每个 Pod 的总分配成本将是分割成本和按比例重新分配的未使用成本的总和。一旦 EC2 成本在 Pod 级别可用,我们可以计算聚合的命名空间级别成本。在这个例子中,命名空间 1 和命名空间 2 的总分配成本分别为 $0.142 和 $0.188。我们还可以使用成本类别或添加到 Kubernetes Pod 的新 EKS 成本分配标签聚合成本,允许我们按所需的业务实体级别计算成本。
成本和使用报告中的新列是什么?
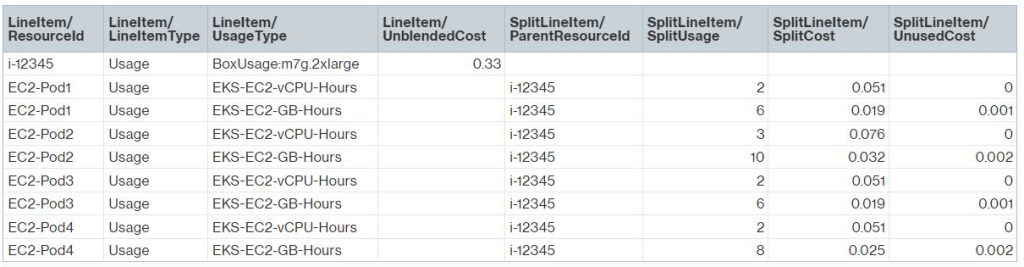
随着 Split Cost Allocation Data 计算 Kubernetes Pod 级别的指标,我们将在 CUR 报告中看到新的列。例如,“SplitLineItem/SplitUsage” 是在指定时间段内分配给 Kubernetes Pod 的 CPU 或内存的使用情况。我们可以查看 CUR 数据字典
获取新 CUR 列的完整列表及其定义。
总结我们的示例,我们可以看到数据将如何在新的 CUR 列中显示。
我们还可以使用 容器成本分配仪表板 在 Amazon QuickSight 中查询和可视化我们的 EKS 成本,以及使用 CUR 查询库 使用 Athena 查询我们的 EKS 成本。